Maps is also known as dictionaries or associative arrays, are fundamental data structures that allow you to efficiently store and retrieve data based on unique keys. This tutorial will cover the basics of maps, including their main ideas, how they are used in different programming languages, and how they are applied in algorithm design.
What is Map Data Structure?
Map data structure (also known as a dictionary , associative array , or hash map ) is defined as a data structure that stores a collection of key-value pairs, where each key is associated with a single value.
Maps provide an efficient way to store and retrieve data based on a unique identifier (the key).
Need for Map Data Structure
Map data structures are important because they allow for efficient storage and retrieval of key-value pairs. Maps provide the following benefits:
- Fast Lookup: Unordered maps allow for constant-time (O(1)) average-case lookup of elements based on their unique keys.
- Efficient Insertion and Deletion: Maps support fast insertion and deletion of key-value pairs, typically with logarithmic (O(log n)) or constant-time (O(1)) average-case complexity.
- Unique Keys: Maps ensure that each key is unique, allowing for efficient association of data with specific identifiers.
- Flexible Data Storage: Maps can store a wide variety of data types as both keys and values, providing a flexible and versatile data storage solution.
- Intuitive Representation: The key-value pair structure of maps offers an intuitive way to model and represent real-world data relationships.
Properties of Map Data Structure:
A map data structure possesses several key properties that make it a valuable tool for various applications:
- Key-Value Association: Maps allow you to associate arbitrary values with unique keys. This enables efficient data retrieval and manipulation based on keys.
- Unordered (except for specific implementations): In most map implementations, elements are not stored in any specific order. This means that iteration over a map will yield elements in an arbitrary order. However, some map implementations, such as TreeMap in Java, maintain order based on keys.
- Dynamic Size: Maps can grow and shrink dynamically as you add or remove elements. This flexibility allows them to adapt to changing data requirements without the need for manual resizing.
- Efficient Lookup: Maps provide efficient lookup operations based on keys. You can quickly find the value associated with a specific key using methods like get() or [] with an average time complexity of O(1) for hash-based implementations and O(log n) for tree-based implementations.
- Duplicate Key Handling: Most map implementations do not allow duplicate keys. Attempting to insert a key that already exists will typically overwrite the existing value associated with that key. However, some map implementations, like multimap in C++, allow storing multiple values for the same key.
- Space Complexity: The space complexity of a map depends on its implementation. Hash-based maps typically have a space complexity of O(n) , where n is the number of elements, while tree-based maps have a space complexity of O(n log n) .
- Time Complexity: The time complexity of operations like insertion, deletion, and lookup varies depending on the implementation. Hash-based maps typically have an average time complexity of O(1) for these operations, while tree-based maps have an average time complexity of O(log n) . However, the worst-case time complexity for tree-based maps is still O(log n) , making them more predictable and reliable for performance-critical applications.
Ordered vs. Unordered Map Data Structures
Both ordered and unordered maps are associative containers that store key-value pairs. However, they differ in how they store and access these pairs, leading to different performance characteristics and use cases.
Ordered Map:
An ordered map maintains the order in which key-value pairs are inserted. This means that iterating over the map will return the pairs in the order they were added.
- Implementation: Typically implemented using a self-balancing binary search tree (e.g., red-black tree ) or a skip list.
- Access: Accessing elements by key is efficient (typically O(log n) time complexity), similar to an unordered map.
- Iteration: Iterating over the map is efficient (typically O(n) time complexity) and preserves the insertion order.
- Use Cases: When the order of elements is important, such as:
- Maintaining a chronological log of events.
- Representing a sequence of operations.
- Implementing a cache with a least-recently-used (LRU) eviction policy.
Unordered Map:
An unordered map does not maintain the order of key-value pairs. The order in which elements are returned during iteration is not guaranteed and may vary across different implementations or executions.
- Implementation: Typically implemented using a hash table.
- Access: Accessing elements by key is very efficient (typically O(1) average time complexity), making it faster than an ordered map in most cases.
- Iteration: Iterating over the map is less efficient than an ordered map (typically O(n) time complexity) and does not preserve the insertion order.
- Use Cases: When the order of elements is not important and fast access by key is crucial, such as:
- Implementing a dictionary or symbol table.
- Storing configuration settings.
- Caching frequently accessed data.
Summary Table:
| Feature | Ordered Map | Unordered Map |
|---|
| Order | Maintains insertion order | No order |
| Implementation | Self-balancing tree, skip list | Hash table |
| Access by key | O(log n) | O(1) average |
| Iteration | O(n) | O(n) |
| Use cases | Order matters, LRU cache | Fast access, dictionaries |
Map Data Structure in Different Languages:
The implementation of the Map Data Structure depends on the programming language. Below is a brief discussion about the map data structure in some popular programming languages.
C++ offers two primary map implementations:
- std::map: This is the standard ordered map, providing the features mentioned above. It uses a red-black tree internally for efficient sorting and lookup operations.
- std::unordered_map: This is an unordered map that uses a hash table for faster lookup operations. However, elements are not stored in any specific order.
Here’s a table summarizing the key differences between std::map and std::unordered_map :
| Feature | std::map | std::unordered_map |
|---|
| Ordering | Ordered based on keys | Unordered |
| Lookup Performance | Slower than std::unordered_map | Faster than std::map |
| Memory Overhead | Higher due to the red-black tree structure | Lower due to the hash table structure |
| Use Cases | When order of elements is important | When fast lookup performance is critical |
Choosing between std::map and std::unordered_map depends on your specific needs. If you require ordered elements and are willing to sacrifice some lookup speed, std::map is a good choice. If lookup performance is critical and order is not important, std::unordered_map is a better option.
In addition to these two main types, C++ also offers:
- std::multimap: This allows storing multiple values for the same key.
- std::unordered_multimap: Similar to std::multimap but uses a hash table.
Java offers several built-in map implementations, each with its own characteristics and use cases:
- HashMap: This is the most commonly used map implementation in Java. It uses a hash table for fast key-value lookups. The order of elements is not maintained, and keys can be any object type that implements the hashCode() and equals() methods.
- TreeMap: This map implementation maintains keys in sorted order based on their natural ordering or a custom comparator. It provides efficient retrieval of elements in sorted order but has slightly slower lookup performance compared to HashMap .
- LinkedHashMap: This map extends HashMap and maintains the order of elements based on their insertion order. This is useful when you need to preserve the order in which elements were added to the map.
- ConcurrentHashMap: This thread-safe map implementation allows concurrent access from multiple threads without the need for external synchronization. It is ideal for multi-threaded applications where concurrent access to the map is required.
- EnumMap: This specialized map is designed to work with enum keys. It provides efficient storage and access for maps where keys are limited to a set of enum values.
Choosing the right map type depends on your specific needs. If you prioritize fast lookups and don’t need to maintain order, HashMap is a good choice. If you need sorted elements or want to preserve insertion order, TreeMap or LinkedHashMap are better options. For multi-threaded applications, ConcurrentHashMap is essential.
Here’s a table summarizing the key differences between the common map implementations in Java:
| Feature | HashMap | TreeMap | LinkedHashMap | ConcurrentHashMap |
|---|
| Ordering | Unordered | Ordered based on keys | Ordered based on insertion order | Unordered |
| Lookup Performance | Faster than TreeMap and LinkedHashMap | Slower than HashMap but efficient for sorted access | Slower than HashMap but efficient for insertion order access | Slower than HashMap but thread-safe |
| Thread Safety | Not thread-safe | Not thread-safe | Not thread-safe | Thread-safe |
| Use Cases | General-purpose key-value lookups | Sorted data, range queries | Preserving insertion order, LRU caches | Concurrent access from multiple threads |
While Python’s built-in dict provides the core functionality for maps, several additional types offer specialized features:
- collections.defaultdict: This type allows you to specify a default value for missing keys. When you try to access a key that doesn’t exist, the default value is returned instead of raising a KeyError . This is useful for avoiding errors when dealing with optional data.
- collections.OrderedDict: This type maintains the order in which key-value pairs were inserted. This is helpful when you need to preserve the order of elements, such as in a log or a queue.
- collections.ChainMap: This type allows you to create a single view of multiple dictionaries. Changes made to the chain map are reflected in all underlying dictionaries. This is useful for combining data from multiple sources.
- Custom Implementations: Python allows you to create your own map types by subclassing the dict class and overriding its methods. This gives you the flexibility to tailor the behavior of the map to your specific needs.
Choosing the right map type in Python depends on your specific requirements. If you need a simple, unordered map, the built-in dict is sufficient. If you need to handle missing keys gracefully, defaultdict is a good choice. If preserving order is crucial, OrderedDict is the way to go. For more complex scenarios, ChainMap or custom implementations can provide the necessary flexibility.
Here’s a table summarizing the key differences between the common map types in Python:
| Feature | dict | collections.defaultdict | collections.OrderedDict | collections.ChainMap |
|---|
| Ordering | Unordered | Unordered | Ordered based on insertion order | Unordered (reflects order of underlying dictionaries) |
| Handling Missing Keys | Raises KeyError for missing keys | Returns the default value for missing keys | Raises KeyError for missing keys | Returns the value from the first dictionary in the chain that has the key |
| Use Cases | General-purpose key-value storage | Handling optional data, avoiding KeyError exceptions | Preserving order of elements, logs, queues | Combining data from multiple dictionaries, configuration files |
While the Dictionary<TKey, TValue> class provides the core functionality for maps, C# offers several additional types for specific use cases:
- SortedDictionary<TKey, TValue>: This type maintains the order of elements based on the key’s implementation of I Comparable<T> . This is useful when you need to iterate over the map in sorted order.
- ConcurrentDictionary<TKey, TValue>: This thread-safe map implementation allows concurrent access from multiple threads without the need for external synchronization. It is ideal for multi-threaded applications where concurrent access to the map is required.
- ReadOnlyDictionary<TKey, TValue>: This read-only wrapper around a Dictionary<TKey, TValue> prevents modifications to the map after creation. This is useful for sharing data that should not be changed.
- Custom Implementations: C# allows you to create your own map types by implementing the IDictionary<TKey, TValue> interface. This gives you the flexibility to tailor the behavior of the map to your specific needs.
Choosing the right map type in C# depends on your specific requirements. If you need a simple, unordered map, the Dictionary<TKey, TValue> class is sufficient. If you need to maintain order, SortedDictionary<TKey, TValue> is a good choice. For multi-threaded applications, ConcurrentDictionary<TKey, TValue> is essential. If you need to prevent modifications, use ReadOnlyDictionary<TKey, TValue> . For more complex scenarios, custom implementations can provide the necessary flexibility.
Here’s a table summarizing the key differences between the common map types in C#:
| Feature | Dictionary<TKey, TValue> | SortedDictionary<TKey, TValue> | ConcurrentDictionary<TKey, TValue> | ReadOnlyDictionary<TKey, TValue> |
|---|
| Ordering | Unordered | Ordered based on keys | Unordered | Unordered (reflects order of underlying dictionary) |
| Thread Safety | Not thread-safe | Not thread-safe | Thread-safe | Not thread-safe |
| Use Cases | General-purpose key-value storage | Maintaining order of elements, sorted access | Concurrent access from multiple threads | Sharing read-only data, configuration files |
While the Map object provides the core functionality for maps, JavaScript offers several additional types for specific use cases:
- WeakMap: This type allows keys to be garbage collected when no other references to them exist. This is useful for storing private data associated with objects without preventing them from being garbage collected.
- Read-only Map: This type prevents modifications to the map after creation. This is useful for sharing data that should not be changed.
- Custom Implementations: JavaScript allows you to create your own map types by subclassing the Map object and overriding its methods. This gives you the flexibility to tailor the behavior of the map to your specific needs.
Choosing the right map type in JavaScript depends on your specific requirements. If you need a simple, unordered map, the built-in Map object is sufficient. If you need to handle weak references or prevent modifications, WeakMap or a read-only map are good choices. For more complex scenarios, custom implementations can provide the necessary flexibility.
Here’s a table summarizing the key differences between the common map types in JavaScript:
| Feature | Map | WeakMap | Read-only Map |
|---|
| Ordering | Unordered | Unordered | Unordered |
| Key Types | Any value, including objects and functions | Objects only | Any value, including objects and functions |
| Handling Weak References | No | Keys can be garbage collected when no other references exist | No |
| Modifiability | Mutable | Not modifiable | Not modifiable |
| Use Cases | General-purpose key-value storage | Storing private data associated with objects | Sharing read-only data, configuration files |
Difference between Map, Set, and Array Data Structure:
| Features | Array | Set | Map |
|---|
| Duplicate values | Duplicate Values
| Unique Values
| keys are unique, but the values can be duplicated
|
|---|
| Order | Ordered Collection
| Unordered Collection
| Unordered Collection
|
|---|
| Size | Static
| Dynamic
| Dynamic
|
|---|
| Retrieval | Elements in an array can be accessed using their index
| Iterate over the set to retrieve the value.
| Elements can be retrieved using their key
|
|---|
| Operations | Adding, removing, and accessing elements
| Set operations like union, intersection, and difference.
| Maps are used for operations like adding, removing, and accessing key-value pairs.
|
|---|
| Memory | Stored as contiguous blocks of memory
| Implemented using linked lists or trees
| Implemented using linked lists or trees
|
|---|
Internal Implementation of Map Data Structure:
The Map data structure is a collection of key-value pairs that allows fast access to the values based on their corresponding keys. The internal implementation of the Map data structure depends on the programming language or library being used.
Map data structure is typically implemented as an associative array or hash table , which uses a hash function to compute a unique index for each key-value pair. This index is then used to store and retrieve the value associated with that key.
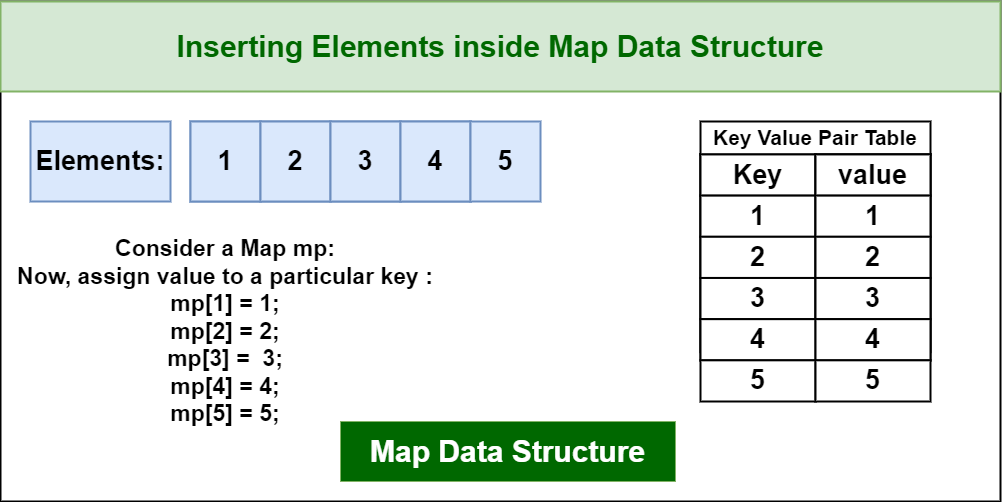
Map Data Structure
When a new key-value pair is added to the Map, the hash function is applied to the key to compute its index, and the value is stored at that index. If there is already a value stored at that index, then the new value replaces the old one.
Operations on Map Data Structures:
A map is a data structure that allows you to store key-value pairs. Here are some common operations that you can perform with a map:
- Insert: we can insert a new key-value pair into the map and can assign a value to the key.
- Retrieve: we can retrieve the value associated with a key and can pass in the key as an argument.
- Update: we can update the value associated with a key and can assign a new value to the key.
- Delete: we can delete a key-value pair from the map by using the erase() method and passing in the key as an argument.
- Lookup: we can look up if a key exists in the map by using the count() method or by checking if the value associated with the key is equal to the default value.
- Iteration: we can iterate over the key-value pairs in the map by using a for loop or an iterator.
- Sorting: Depending on the implementation of the map, we can sort the key-value pairs based on either the keys or the values.
Below is the Implementation of the above Operations:
C++
#include <iostream>
#include <map>
int main()
{
// Creating a map
std::map<std::string, int> m;
// Inserting a new key-value pair
m["apple"] = 100;
m["banana"] = 200;
m["cherry"] = 300;
// Retrieving the value associated with a key
int value = m["banana"];
std::cout << "Value for key 'banana': " << value
<< std::endl;
// Updating the value associated with a key
m["banana"] = 250;
value = m["banana"];
std::cout << "Updated value for key 'banana': " << value
<< std::endl;
// Removing a key-value pair
m.erase("cherry");
// Iterating over the key-value pairs in the map
std::cout << "Key-value pairs in the map:" << std::endl;
for (const auto& pair : m) {
std::cout << pair.first << ": " << pair.second
<< std::endl;
}
return 0;
}
import java.util.HashMap;
import java.util.Map;
public class GFG {
public static void main(String[] args)
{
// Creating a map
Map<String, Integer> m = new HashMap<>();
// Inserting a new key-value pair
m.put("apple", 100);
m.put("banana", 200);
m.put("cherry", 300);
// Retrieving the value associated with a key
int value = m.get("banana");
System.out.println("Value for key 'banana': "
+ value);
// Updating the value associated with a key
m.put("banana", 250);
value = m.get("banana");
System.out.println(
"Updated value for key 'banana': " + value);
// Removing a key-value pair
m.remove("cherry");
// Iterating over the key-value pairs in the map
System.out.println("Key-value pairs in the map:");
for (Map.Entry<String, Integer> pair :
m.entrySet()) {
System.out.println(pair.getKey() + ": "
+ pair.getValue());
}
}
}
# Creating a map
d = {'key1': 'value1', 'key2': 'value2', 'key3': 'value3'}
# Adding a new key-value pair
d['key4'] = 'value4'
# Retrieving the value associated with a key
print(d['key2']) # Output: value2
# Updating the value associated with a key
d['key2'] = 'new_value2'
# Removing a key-value pair
del d['key3']
# Iterating over the key-value pairs in the map
for key, value in d.items():
print(key, value)
using System;
using System.Collections.Generic;
public class GFG {
public static void Main(string[] args)
{
// Creating a dictionary
Dictionary<string, int> m
= new Dictionary<string, int>();
// Inserting a new key-value pair
m.Add("apple", 100);
m.Add("banana", 200);
m.Add("cherry", 300);
// Retrieving the value associated with a key
int value = m["banana"];
Console.WriteLine("Value for key 'banana': "
+ value);
// Updating the value associated with a key
m["banana"] = 250;
value = m["banana"];
Console.WriteLine("Updated value for key 'banana': "
+ value);
// Removing a key-value pair
m.Remove("cherry");
// Iterating over the key-value pairs in the map
Console.WriteLine("Key-value pairs in the map:");
foreach(KeyValuePair<string, int> pair in m)
{
Console.WriteLine(pair.Key + ": " + pair.Value);
}
}
}
// This code is contributed by prasad264
// Creating a map
let m = new Map();
// Inserting a new key-value pair
m.set("apple", 100);
m.set("banana", 200);
m.set("cherry", 300);
// Retrieving the value associated with a key
let value = m.get("banana");
console.log("Value for key 'banana': " + value);
// Updating the value associated with a key
m.set("banana", 250);
value = m.get("banana");
console.log("Updated value for key 'banana': " + value);
// Removing a key-value pair
m.delete("cherry");
// Iterating over the key-value pairs in the map
console.log("Key-value pairs in the map:");
for (let pair of m.entries()) {
console.log(pair[0] + ": " + pair[1]);
}
OutputValue for key 'banana': 200
Updated value for key 'banana': 250
Key-value pairs in the map:
apple: 100
banana: 250
Advantages of Map Data Structure:
- Efficient Lookup: Maps provide constant-time (O(1)) average-case lookup of elements based on their keys.
- Flexible Key-Value Storage: Maps can store a wide variety of data types as both keys and values.
- Unique Keys: Maps ensure that each key is unique, allowing for efficient association of data.
- Fast Insertions and Deletions: Maps support fast insertion and deletion of key-value pairs, typically with logarithmic (O(log n)) or constant-time (O(1)) average-case complexity.
- Intuitive Data Representation : The key-value pair structure of maps offers an intuitive way to model real-world relationships.
Disadvantages of Map Data Structure:
- Overhead for Key Storage : Maps require additional memory to store the keys, which can be more space-intensive than other data structures like arrays.
- Potential for Collisions: In hash table implementations of maps, collisions can occur when multiple keys hash to the same index, leading to performance degradation.
- Ordering Constraints: Some map implementations, such as binary search trees, impose ordering constraints on the keys, which may not be suitable for all applications.
- Complexity of Implementation: Implementing certain map data structures, like self-balancing binary search trees, can be more complex than simpler data structures.
Applications of Map Data Structure:
- Indexing and retrieval: Maps are used to index elements in an array and retrieve elements based on their keys.
- Grouping and categorization: Maps can be used to group elements and categorize them into different buckets.
For example , you can group employees based on their departments, cities, or salary ranges. - Network routing: Maps are used in computer networks to store information about routes between nodes.
The information stored in the map can be used to find the shortest path between two nodes. - Graph algorithms: Maps can be used to represent graphs and perform graph algorithms, such as depth-first search and breadth-first search.
Frequently Asked Questions (FAQs) on Map Data Structure:
1. What is a Map Data Structure?
A map is a data structure that stores key-value pairs, allowing for efficient lookup, insertion, and deletion of elements based on unique keys.
2. What are the common implementations of maps?
Common implementations of maps include hash tables, binary search trees, and AVL trees, each with their own strengths and trade-offs.
3. What are the time complexities for common operations on maps?
Lookup, insertion, and deletion operations in maps typically have average-case time complexities of O(1) for hash tables and O(log n) for binary search trees.
4. How do maps differ from arrays or lists?
Maps provide constant-time access to elements based on unique keys, while arrays and lists rely on numerical indices, which can be less efficient for certain use cases.
5. What are the common use cases for maps?
Maps are widely used for tasks like caching, databases, compilers, and algorithm design, where efficient key-value storage and retrieval are essential.
Please Login to comment...